I. Einleitung
- serielle Algorithmen
- basieren auf
- von-Neumann-Rechner
- also:
- Instruction set:
- Speicher lesen und schreiben
- grundlegende arithmetische Operationen
- beurteilt nach
Komplexitðt in
- Zeit
- Raum
- Beschreibung, Beschreibungskomplexitðt
- parallele Algorithmen
- haben verschiedene Modelle
- beurteilt nach Kosten
- Zeit á Prozessorenzahl
- hðufigster Ansatz
- & AKL: Introduction to parallel Algorithms
- → Modell?
- → WORK
- abstrakter Zugang
- (spðter)
- es ist sehr wichtig, welches Modell verwendet wird
- Kosten sind davon abhðngig
- wesentliche Punkte f■r parallele Rechnungen
- computational concurrency
- Prozessor-Allokation
- Zuordnung der Prozessoren
zu einzelnen Aufgaben
- Scheduling
- in welchen Zeitabschnitten sollen welche Aufgaben erf■llt sein?
- Communication
- wie kommunizieren einzelne Prozessoren miteinander?
- wie werden Zwischenergebnisse ausgetauscht?
- Synchronisation
- synchrones Modell
- asynchrones Modell
- MaÔe:
- Problem P
- serielle Komplexitðt T*(n)
- Inputgr—Ôe n
- Komplexitðt des besten m—glichen sequentiellen
- wenn die Komplexitðt des bestm—glichen Algorithmus nicht bekannt ist,
wird auch oft die Komplexitðt des besten bekannten Algorithmus verwendet
- p - Zahl der Prozessoren
- Tp(n) - Zeit des untersuchten parallelen Algorithmus
bei Einsatz von p Prozessoren
| Speedup: Sp(n) = |
T*(n) |
|
| Tp(n) |
- ist in der Regel ≥ 1
- gibt an, wieviel mal schneller ein paralleler Algorithmus ist
- Ideal wðre: Sp(n) ≈ p
- Anmerkung:
- es ist T1(n) die Rechenzeit auf einem "Parallelrechner" mit nur einem Prozessor
- oft gilt T1(n) > T*(n)
- allgemeine Speed-Up Formel
| Effizienz Ep(n) = |
T1(n) |
|
|
pñTp(n) |
- stets ≤ 1
- gute Effizienz: Wert liegt nahe bei 1
- T1(n) = Paralleler Algorithmus f■r einen Prozessor
- Schranke: T∞(n)
- diese Zeit kann nicht durch noch mehr Prozessoren verbessert werden
- Tp(n) ≥ T∞(n) f■r jeden beliebigen Wert von p
- ß Die Effizienz eines Algorithmus nimmt mit wachsendem p schnell ab
- Modelle

DAGs- Hypercubes / Netzwerkmodell
- ber■cksichtigt das Kommunikationsmodell
- MaÔe
- Diameter = Durchmesser = maximaler Abstand zwischen einem Paar von Knoten
- maximaler Grad = Anzahl der Kanten des Knotens mit den meisten Kanten
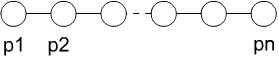
erster Ansatz: Prozessoren k—nnen mit Nachbarn kommunizieren
- sehr eingeschrðnkt
- Kommunikation mit 1 bis 2 Nachbarn in O(1) m—glich
- Kommunikation mit Prozessoren, die nicht direkt benachbart sind
- geht nur ■ber dazwischenliegende Prozessoren
- dauert lðnger
- Topologien
- lineares Array
- jeder Prozessor Pi ist verbunden mit Pi-1 und Pi+1
- Ausnahme: Prozessoren am Rand
- Diameter ist = p-1
- maximaler Grad = 2
- Ring
- lineares Array, dessen ðuÔere Prozessoren noch verbunden werden
- also: Pp ist mit P1 verbunden

besser:
Kommunikation geht mit bis zu 4 Nachbarn in O(1)
- besser
- Kommunikation geht mit bis zu vier Nachbarn in O(1)
- Gitter besteht aus p = m2 Prozessoren
- jeder Prozessor Pi,j ist verbunden mit den Prozessoren Pi±1, j und Pi, j±1
- Durchmesser = √p
- maximaler Knotengrad = 4

weitergedacht
- d-dimensionaler Hypercube
- besteht aus 2d Prozessoren
- Durchmesser = d = log p
- Knotengrad ist stets d

Beispiel f■r 3-D Hypercube
- Diameter ist log2 p
- Distanz = Anzahl unterschiedlicher Bits in der Prozessorzahl
- 0-1-Codierungen → Nachbarschaften
- Haming-Distanz zwischen zwei benachbarten Knoten = 1

4-D-Hypercube
- Shared-Memory-Modell
- (hier behandelt)
- Grund: DAGs und Hypercubes nicht geeignet
um allgemeine Paradigmen zu beschreiben
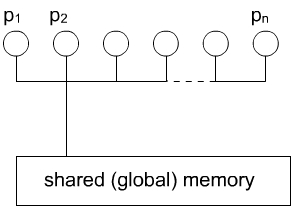
- Idee: Prozessoren haben einen gemeinsamen Speicher
- lesen des Speichers kostet O(1)
- Schreiben in Speicher kostet O(1)
- Prozessoren k—nnen ■ber Speicher in O(1) kommunizieren
- keine direkte Kommunikation zwischen Prozessoren
- k—nnen auch jweils noch zusðtzlich einen eigenen Speicher haben
- Unterscheidung
- asynchrones Modell
- etwas komplexer
- es muss garantiert werden, dass Zwischenergebnisse bereitstehen, bevor auf sie zugegriffen wird
- Q hier nicht behandelt
- synchrones Modell
- Beispiel Ax> = y>
- Matrix-Vektor-Multiplikation

synchron parallel

asynchron parallelisiert
- Prozessor 1 rechnet Zeile 1 x Vektor
- Prozessor 2 rechnet Zeile 2 x Vektor
- ß einzelne Berechnungen sind unabhðngig von einander
- Problem: letzter Prozessor darf erst aktiv werden,
wenn andere fertig sind
- Vorteile
- hochentwickelte Techniken und Methoden f■r den Umgang
mit vielen verschiedenen Klassen von Problemen
- l—st algorithmische Details bez■glich Synchronisation und Kommunikation auf
- erlaubt das Fokussieren auf strukturelle Eiigenschaften des Problems
- deckt verschiedene wichtige Parameter der parallelen Berechnung ab
- schlieÔt explizites Verstehen der Operationen der einzenen time units ein
- die Paradigmen auf der PRAM haben sich als robust erwiesen:
- viele der Netzwerk-Algorithmen k—nnen direkt aus den PRAM-Algorithmen abgeleitet werden
- viele PRAM-Algorithmen k—nnen auch auf Netzwerke mit begrenztem Knotengrad ■bertragen werden
- Darstellung "Beschreibung" von Algorithmen nach Levels
- 1 Allgemeine Beschreibung der Wirkung des Algorithmus
- 2 Darstellung der Abfolge von time units
- sog. Work-Time-Darstellung
- 3 Prozessorallocation → Realisierung der einzelnen Time-Units